

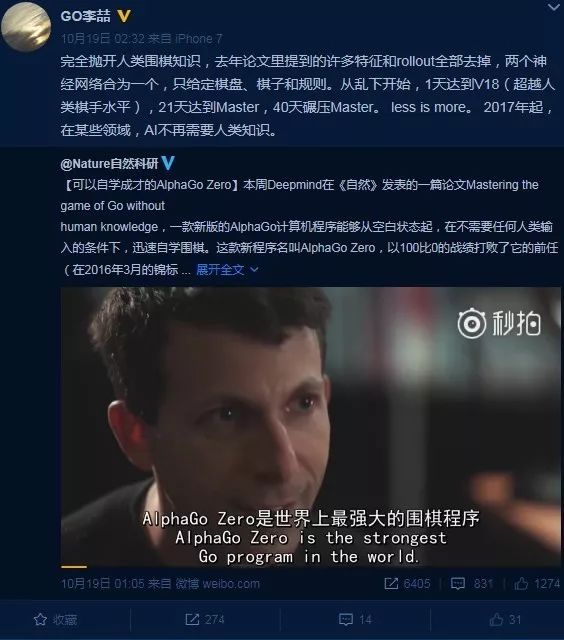
�����µ��˹����ܵ����ˣ������ǰ�����ԪAlphaGo Zero���ڶ�����Ӯ�º�����������ʯ�ǰ��AlphaGoʱ��AlphaGo Zeroȡ����100��0��ѹ����ս�������������ո߳�������
����Χ��֮��������
������|��̳�ܱ����� л��
������Alpha Go��Ҫ�����ö���˹����ܵ����ˣ������ǰ�����ԪAlpha Go Zero����10��19�����硶��Ȼ����־���ߵ��ذ������У���ϸ�����˹ȸ�DeepMind�Ŷ����µ��о��ɹ���
����
����������Ԫ��ȫ���㿪ʼ������Ҫ�κ���ʷ����ָ����������Ҫ�ο������κε�����֪ʶ����ȫ���Լ�ǿ��ѧϰ�Ͳ���, ��������Զ��������������ս��ʤ��������������100��0��
����
����2016��3�£���һ�Ρ��˻���ս����Alpha Go1.0��4��1����14������ھ����������ʯ�ŶΣ�
����
������ף�Alpha Go�����滯��Master�����϶��������60��ʤ������硣2017��5�µڶ��Ρ��˻���ս����Alpha Go2.0��3��0ʤ�½�ŶΣ��˺������������˶��ġ�
����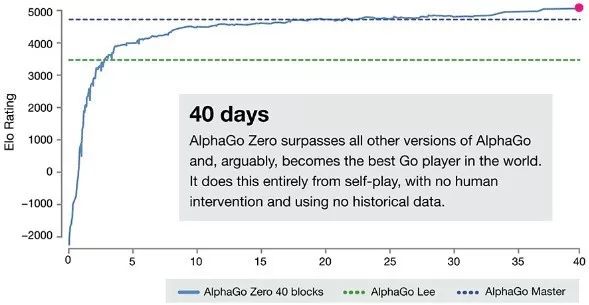
���������������ŶӲ�δֹͣ�о��������о������ijɹ���Alpha Go Zero���밢��������ͬ��������Ԫ����ѧϰ�������ף����������ջ��������ͨ�����һ���������40��ʱ�䣬����Ϊ��ѹMaster���˹����ܡ�
������������λ�����ڡ���Ȼ����־������Ԫ��������˵��������Ŀ��ֺ��չ���ְҵ���ֵ��·�����������˵����������Χ���ϼ�ǧ����ǻ۽ᾧ������������ȫ����������Ԫ�����̿�������dz����죬�ŷ��Ȱ����������һ���ʱʹ���Ĺ��и��Ӳ���˼�顣����ʱԽ�ŶεĻ�˵���ǣ�����δ�����ŷ���
����Alpha Go Zero֮�����ܵ��Լ�����ʦ��������һ�ֽ�ǿ��ѧϰ����ģʽ��ϵͳ��һ����Χ��һ����֪�������翪ʼ�������������һ��ǿ�������㷨��ϣ����Ҷ��ġ�
����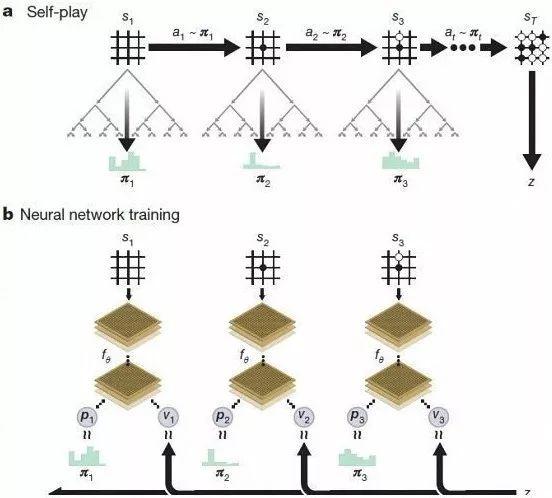
�����ڶ��Ĺ����У������粻�ϵ�����������Ԥ��ÿһ�����Ӻ����յ�ʤ���ߡ�������������������������ϳ�һ����ǿ���°汾Alpha Go Zero���������ѭ����ÿ��һ�֣�ϵͳ�ı��־����һ��㣬���Ҷ��ĵ�����Ҳ���һ��㡣������Խ��Խȷ��Alpha Go Zero�İ汾ҲԽ��Խǿ��
�������ּ����ȴ�ǰ���а汾��Alpha Go����Ϊǿ��������Ϊ���������ܵ�����֪ʶ�����ƣ����ܹ���Ӥ����İ�ֽ״̬��ֱ������������ǿ������֡���Alpha Go����ѧ��
����
������Ϊ��Щ�Ľ���Alpha Go Zero�ı��ֺ�ѵ��Ч�ʶ����˺ܴ����������ͨ��4��TPU��72Сʱ��ѵ����ʤ��֮ǰѵ����ʱ�����µ�ԭ��Alpha Go�����Ҷ���40���lpha Go Zero��ø�Ϊǿ�����˴�ǰ���ܵ���Χ���һ�˿½��Master�༴Alpha Go2.0�档
����
�����½������һ����������������ѧϰ��alphago����ǿ�ġ�������Alphago�����ҽ�������������̫�����ˡ���Alpha Goͨ������������Ҷ��ģ����㿪ʼ����Χ�壬�ڶ̶̼����ڻ������༸ǧ����е�֪ʶ��Alpha Go ZeroҲ�������µ�֪ʶ����չ�����Ƴ���IJ��Ժ����У������ڶ�ս����ʯ�Ϳ½�ʱ�������Щ�����ӳ��ȴ�ָ�ʤһ�
������������Щ�����Ե�ʱ�̸����������ģ��˹����ܻ��Ϊ�����ǻ۵���ǿ�����������������������������ٵ�һЩ�Ͼ���ս�����ܲŸոշ�չ����������Alpha Go Zero�Ѿ��߳���ͨ������Ŀ��Ĺؼ�һ����������Ƶļ�������Ӧ���������ṹ�����⣬���絰�����۵��������ܺĺ�Ѱ���²����ϣ����ܴ��������������ͻ�ơ�
����
�����Ȱ���������Alpha Go����Ϊǿ��ͽ�������İ�����Ԫ��Alpha Go Zero��������Χ����ٴα��������Ŷη�������20�겻��3�찡�����ǵ��˸У�����Ľ�������
����������Ԫͨ����ѧ��ΪΧ���һ���֣����·���Ȼ�߸����������ס���·����������ܿ���������������·��ѭ����ִ�ڵ�һ�ֻ�����λ��Ȼ��ֱ�ӵ�Է���λ�ǵ�����������Ҳ��Ŀǰ�����Ǽ������ϵ��·���
����
��������Master�ڲ���һЩ������·��塢��·����ľ��������·��������Ԫ�ڼ����ϸ�������ɵij��������Master������40��ʱ�����һ�Ű�ֽ����ѹMaster�ĸ��֣������ijɳ��ٶȲ����������ѡ�
����
��������η���������ȫ������Χ��֪ʶ��ȥ���������ᵽ������������rolloutȫ��ȥ���������������Ϊһ����ֻ�������̡����Ӻ������¿�ʼ��1��ﵽV18����Խ��������ˮƽ����21��ﵽMaster��40����ѹMaster��2017������ijЩ����AI������Ҫ����֪ʶ����
����
��������������֮����ַ������йذ�����Ԫ����������Ϊ�������֣����ر��ˡ���ǧ��ǰ����涨�����Ӿ�����λ����Alpha Go Zero��Ȼ����ռ����λ�����������·����ܱ������⣬�����ۻ����ɵ�Χ����ʶ����ȫ��ѧϰ��Zero������ʶ����ǿ����㷨��ǰ������չ�����������Ⱥ���������
����������Ԫ������ѧϰΧ�壬��ȫ�����������Χ�����ۺ�֪ʶ�ľ��ޣ�ͨ��ǿ�������ѧϰ���ܴﵽ��һ����ˮ��������һЩ����˼·�����༸ǧ�������ǻ۳ɹ���;ͬ�飬��Ҳ֤������Χ�����۵Ŀ�ѧ�ԡ������ԣ�������ȫ�ǡ����ɡ���
����
���������������ˣ�Alpha Go Zero������ְҵ�����Լ�Χ����ѵ��·�Dz������ߵ���ͷ���˹�����ר�ҡ��������������ɴ�ѧ�����ط�У���ں����Ϊû��Ҫ��ô���ۣ��������Ͱ˾�ʮ������˹���������о�ӭ����һ�����ѧ��Ȧ���˳�ǧ����ƪ��������������ģ�����Ƶ�ѵ�����Ż��ٵ����и�ҵ��Ӧ�ã��������֮����
����������Ъ����ѧ�˹�����ʵ��������Satinder SinghҲ���������ƹ۵㣺�Ⲣ���κν����Ŀ�ʼ���˹����ܺ�������������ȣ���֪������Ȼ�������ޡ�
������ʵ����������Ҳ�ã�������ԪҲ�գ��������ǵ��ŷ��ӽ�Χ��֮�������վ�û�и��顢û�и��ԣ������ij��������������������������Ե����������ǵ�ȷ��ȷ�����������ԡ�����ʧ����������������ϲ�ְ������������Ȥ��
����Alpha��ϣ����ĸ���еĵ�һ����ĸ������ʾ����һ������������ˡ�����Go����Դ��������Χ��ķ���������ע��Ϊ��go������Ӣ�go���Ķ������в��졣��ȻΧ����Դ���й��������ձ��������ƹ��м����ף����Թ���Χ���������������
����
������һ����ȫ���Բ���Ѱ��·�������ֻ��Ѱ��·�ķ��볣�������˸е���Ť��
�����ֵ��˸�λ�Զ���ʱ�̣�
����
����ijλ����˵��Ӧ�ýС�������������
����
��������ͬ��˵��Ӧ�ýС���������ȥ����
����
����
������������˵��Ӧ�ýС������������ߡ���
����
����
����ijλ��֪����ʿ¶��Ӧ�ýС����������㡱��
����
������Ȼ�����ˣ�Ҳ����С����á�������Χ�塱����뷨����ȷ�ƺ�Ӧ�û��Ǹ����Ϲ��һ�㡣
����ʵϰ�༭|С��
 )
)