

����ZM-GO
����
������ע
����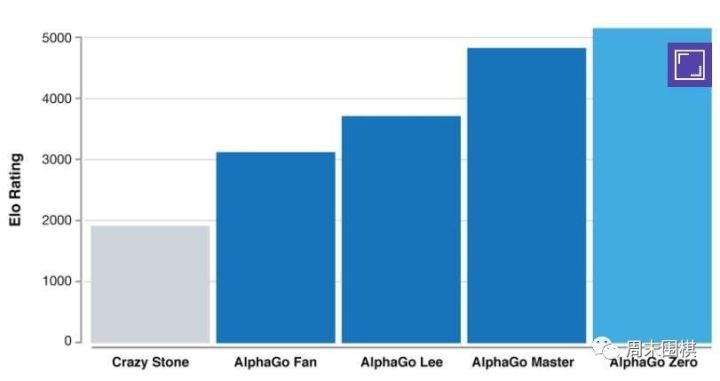
����AlphaGo�����ķ��������Ԥ�棬��Ԥ�ף�����ͻ��������ʯ���쾪�������������������֣�����С�����ϣ������Ե���ô������������ժҪ����һƪ�ö����Ѿ����ˣ�����ֻ������ȫһЩ�ܱ���Ϣ��
����AlphaGo�������漰��83�����ײμ�����-���״�ȫ-���ײ���AlphaGo����ʷ
����
����
������ʿ�½ࣺһ����������������ѧϰ��alphago����ǿ��...����alphago�����ҽ�������...����̫������
����
���������ȫ������Χ��֪ʶ��ȥ���������ᵽ������������rolloutȫ��ȥ���������������Ϊһ����ֻ�������̡����Ӻ������¿�ʼ��1��ﵽV18����Խ��������ˮƽ����21��ﵽMaster��40����ѹMaster�� less is more�� 2017������ijЩ����AI������Ҫ����֪ʶ��
����Nature��ԭ�ģ�
������������ѧ�ɲŵ�AlphaGo Zero������Deepmind�ڡ���Ȼ��������һƪ����Mastering the game of Go without human knowledge��һ���°��AlphaGo����������ܹ��ӿհ�״̬���ڲ���Ҫ�κ���������������£�Ѹ����ѧΧ�塣����³�������AlphaGo Zero����100��0��ս�����������ǰ�Σ���2016��3�µĽ������У���ǰ�δ����Χ��ھ�Lee Sedol����
�����˹����ܵ������ս���з�һ���ܴ��㿪ʼ���Գ������ˮƽѧϰ���Ӹ�����㷨��Ϊ�˴������Χ������ھ�����ѧ����ѵ����һ��AlphaGoʱ��ͬʱ�õ��˼ලʽѧϰ�������ϰ���������רҵѡ�ֵ����岽�裩�ͻ������Ҷ��ĵ�ǿ��ѧϰ���ǿ�AlphaGo��ѵ�����̳��X���£��õ���̨������48��TPU��������ѵ�������רҵоƬ����
����
����AjaHuang�罻ƽ̨ԭ�ģ�
������Һã��҂��ܸ��d�c��ҷ���AlphaGo�ĵ�2ƪՓ�ģ��dz��s��AlphaGo�F��ٴε���������피�ġ���Ȼ���s�I��
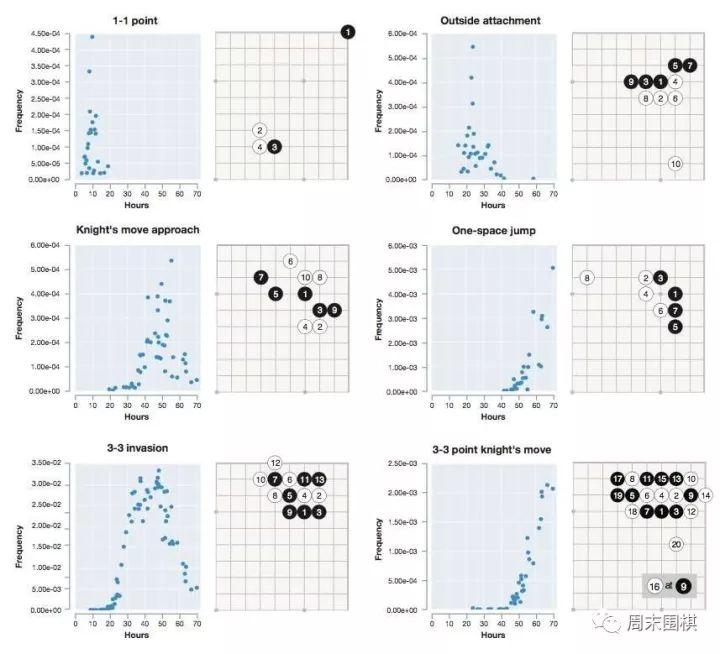
�����@ƪՓ�Ľ�B��AlphaGo Zero��Ҳ������ȫÓ�x���֪�R��AlphaGo�汾����Ҫ�ɹ����£�
����- AlphaGo Zero�����_ʼ���ҌW�����塣
����- �H�H36С�r�ᣬAlphaGo Zero�������ҌW���������������л�������Ҫ�ć���֪�R���_�����c����ʯ�ŶΌ����AlphaGo v18����ͬˮƽ��
����- 30���ᣬ�����M����AlphaGo Zero�_����Master��ˮƽ��Master������ھW���_��60�B�ٵ�AlphaGo�汾��
����- 40���ᣬAlphaGo Zero����Master�_����90%���ʣ��ɞ���ʷ�ԁ�AlphaGo����汾��
����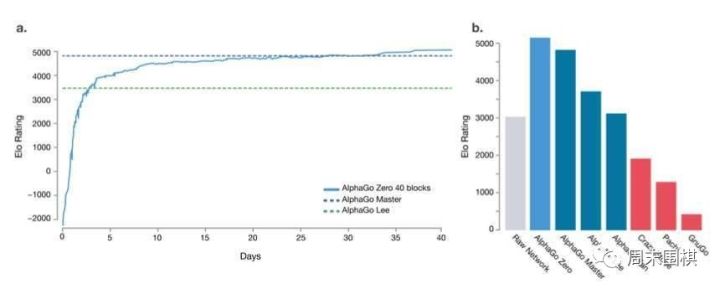
�����mȻAlphaGo Zero�]�й��_���^�壬��Փ�����҂�������AlphaGo Zero��80����(�x�Բ�ͬ�A�ε����ҌW��)��������о����ć��弼�g�ĽǶȁ��f��AlphaGo Zero���l�F�ć����^��·��c��ʽ�ȵȣ��^���c��ć����^����һ�µģ��@Ҳ�g�Ӻ��������ǧ���ԁ�����о��ărֵ��AlphaGo Zero�����L�e�Ñ𣬁K��Ҳϲ�gֱ���c33����Փ�ă��݁��f���@��Ҫ��һƪ�����W����Փ�ģ��P�I���g��춏����W��Ӗ��pipeline��Ч�ܘO��
����ᘌ��@ƪՓ�Ļ�AlphaGo��Ҫ�ᆖ�����ѣ�Ո���������AlphaGo AMA��AlphaGo�F꠵�David Silver�cJulian Schrittwieser���ھ���Ӣ�Ļش��ҵĆ��}��
����
������������ҹ��С��ֻ�뾲���Ĵ����ס����ִ������һ��AlphaGo Zero�����ף��о������⼸ʮ�������壬�µĻ��������ס�
���� END ����
����Since2010
 )
)
