

高通第四代汽车SoC芯片分析,聚焦CPU,AI无所谓
高通在汽车领域快速崛起,垄断中高端座舱领域,但在高通整体营收上,汽车业务所占比例很低。在其最近的财季里,高通手机领域收入62亿美元,汽车业务收入6.03亿美元,IoT业务收入12亿美元。高通近期特别聚焦于AI PC领域,其潜在的市场规模远高于市场,看看英特尔的利润率便知AI PC的利润率也不会低于汽车领域。

图片来源:AnandTech
高通也在2024年Computex大会上做了“PC产业将开始重生(Reborn)”的演讲。

图片来源:AnandTech
高通的第四代汽车SoC芯片仍然是和笔记本电脑、手机等共用核心架构,这样做并无不妥,如今汽车SoC芯片越来越像PC用的CPU,特别是和AI PC的CPU的要求几乎完全一致。
图片来源:AnandTech
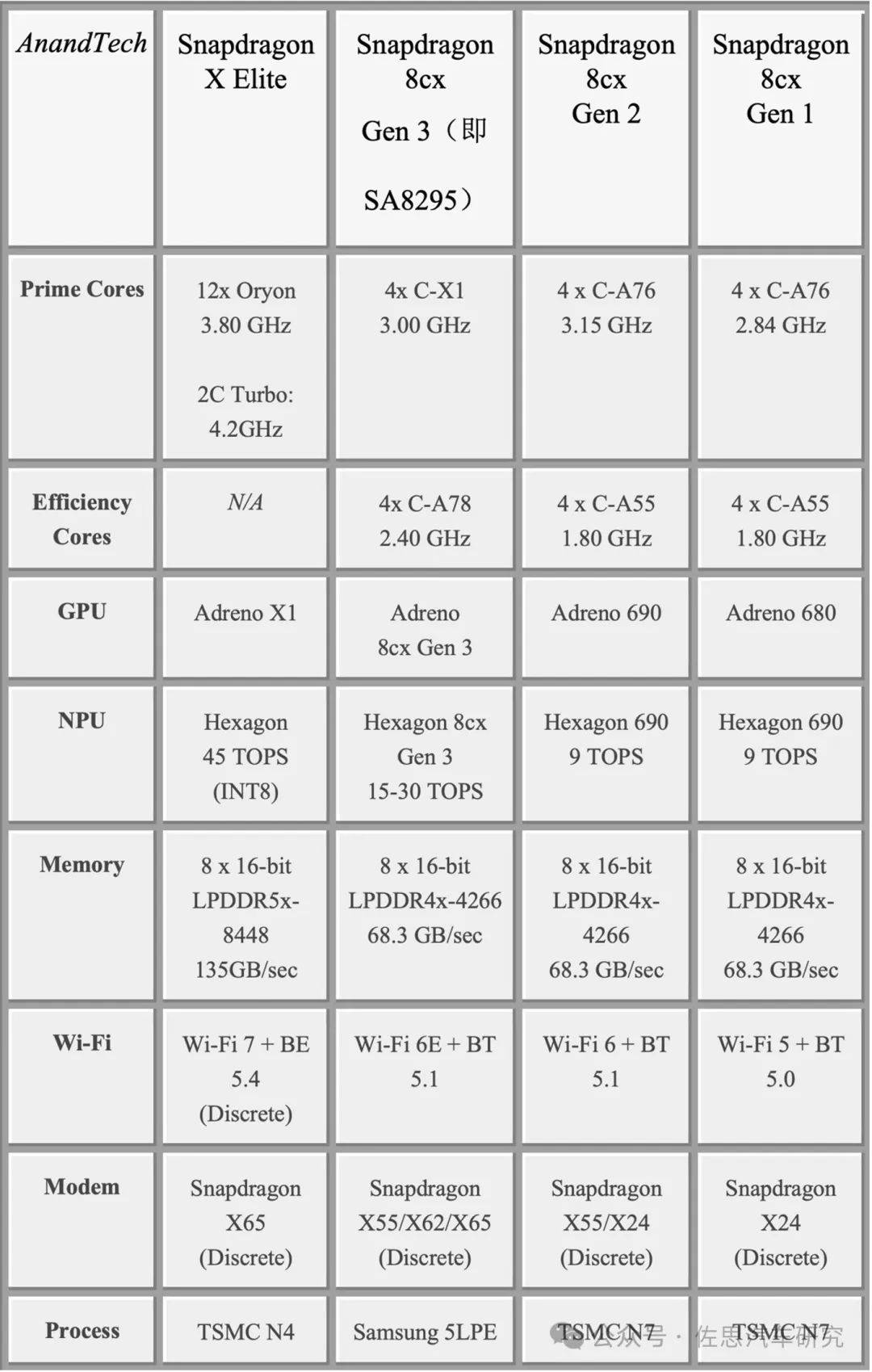
高通第三代代表作SA8295实际就是笔记本电脑领域里的Snapdragon 8cx Gen 3,高通第四代大概率就是Snapdragon X Elite的车规版,不会有太大差异。
图片来源:AnandTech
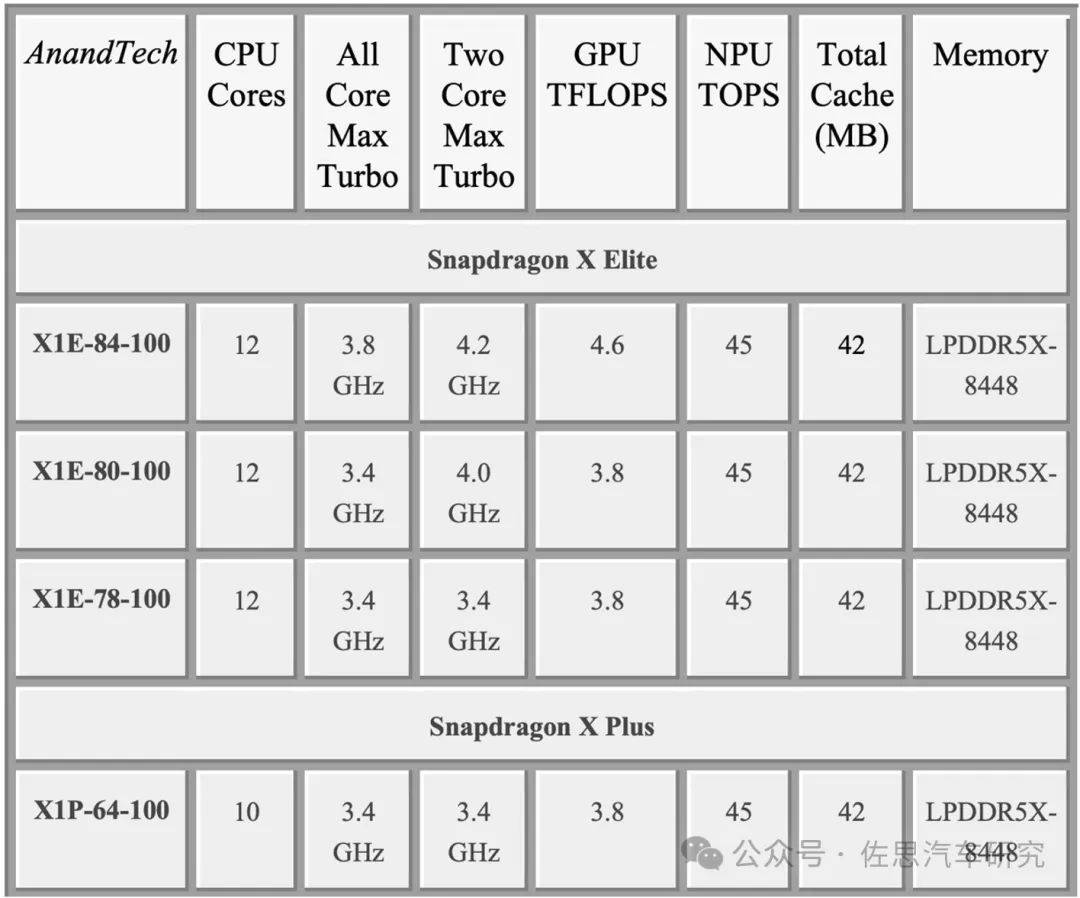
Snapdragon X Elite有三款芯片,主要差别是CPU的频率。高通也罕见公开了Snapdragon X Elite的详细架构信息,基本上完全聚焦于CPU领域,花了90%的篇幅讲解,对AI则一句带过,从关键的存储带宽135GB/s看,虽然较第三代提升了一倍,但与2019确定设计范围的英伟达Orin高达205GB/s的带宽相比,仍然很低。
高通更多地考虑汽车座舱和L2级的舱驾一体,这样的市场定位不需要太高的AI性能,45TOPS足以满足99.9%的应用场景,座舱领域所谓的大模型AI都完全依赖云端计算,端侧部署成本太高,可能高达数千美元,即便端侧部署,体验也和云端计算有很大差距。
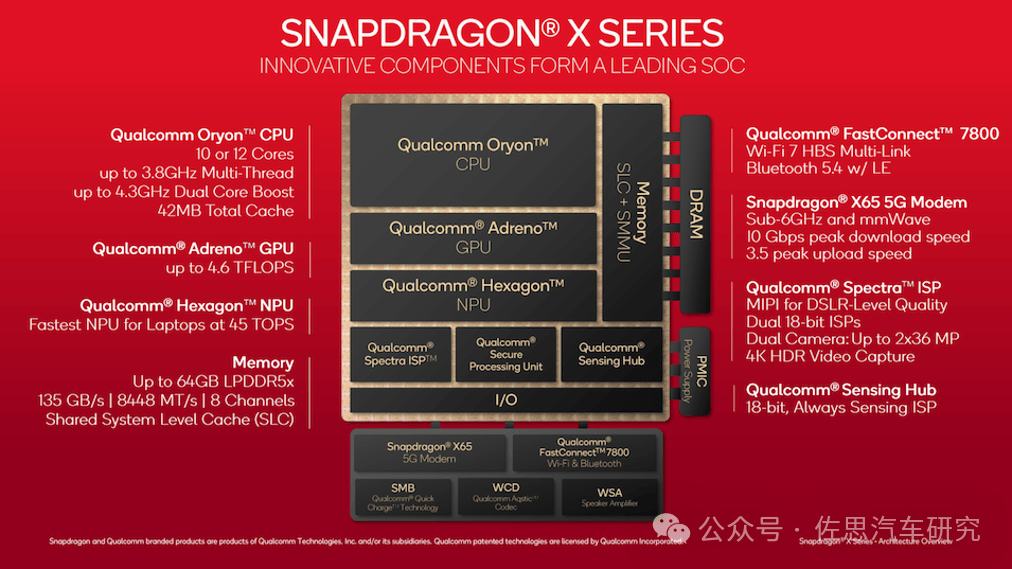
高通Snapdragon X系列芯片架构
图片来源:AnandTech
高通对Snapdragon X系列芯片的Oryon CPU是这样描述的:Oryon CPU Architecture: One Well-Engineered Core For All,能够适用于所有领域。

图片来源:AnandTech
高通采用全大核心设计,有两个核心的频率可以加速,这种全大核心设计也用在高通SA8775上,SA8295的四个大核心则是Kryo 695,最高频率是2.5GHz,四个中核心是Kryo 670 Gold,最高频率2.05GHz,SA8775的8核心完全相同,最高运行频率都是2.35GHz,Kryo 680 Gold Prime和Kryo 695一样都是基于ARM Cortex-X1而来的。

图片来源:AnandTech
Oryon采用共享L2缓存的设计,通常L2缓存都是针对每个核心的,不共享,且规模很小,如SA8775的L2缓存是512kB。一般L3缓存是几个核心共享的,如SA8295是8MB的L3缓存,SA8775是4MB的L3缓存。Oryon的共享缓存高达12MB,每个核心可以分到3MB,这样的规模足以和英特尔Xeon这样的服务器芯片媲美,当然成本也增加很多,估计车规版会减小到4-8MB。
Oryon的前端部分

图片来源:AnandTech
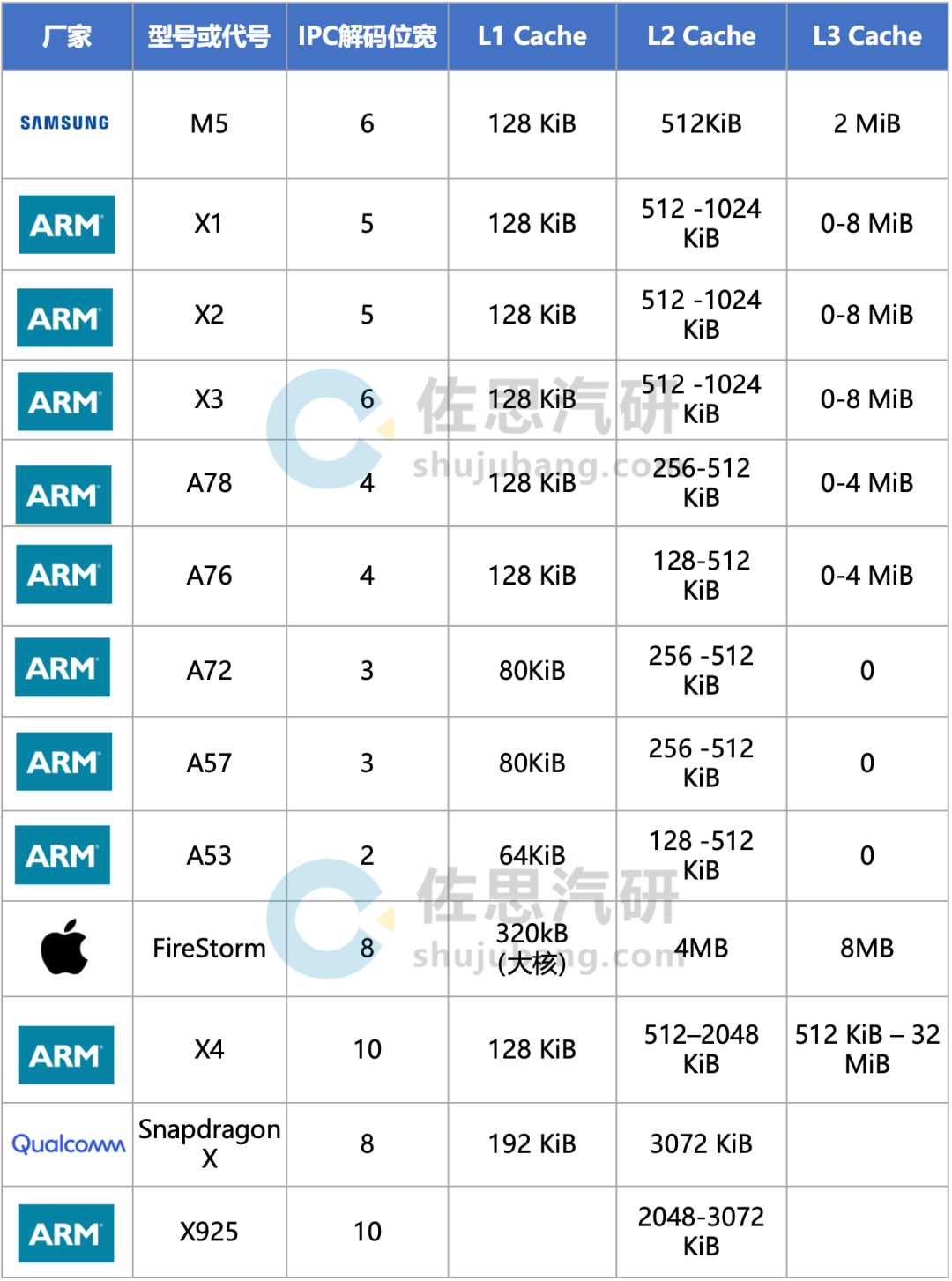
ARM架构的性能对比表
整理:佐思汽研
对于CPU,关键的参数主要有两个,一个是IPC解码宽度,另一个就是缓存,ARM是挤牙膏式的,每年做一次小升级,让利润最大化。苹果则一步到位,性能最大化,以至于苹果连续数年都无法升级性能,安卓手机受困于ARM的挤牙膏,性能始终无法和苹果看齐,这也是高通抛弃ARM的主要原因。即便如此,Snapdragon x系列单核性能仍然无法和苹果匹敌,很简单,L2缓存仅为3MB,还是低于苹果的4MB。IPC解码宽度方面,Snapdragon x系列是8位,远比SA8295用的ARM X1要高。
受高通抛弃的刺激,ARM也发狠,X4和2024年宣布的旗舰X925的IPC解码宽度都是10位,比苹果还高,用X925的单核性能肯定可以超过苹果。

图片来源:AnandTech
Oryon的后段IXU两大特色,一是对AI运算的支持,包括128比特宽度的NEON SIMD(这个宽度属实有点窄了,英特尔最高已是1024比特),每周期最高4个FP32精度的ADD/WUL/MLA的指令执行,支持INT8\INT16\FP16\FP32多种精度,这些基本上是常规操作,不过高通最高可以支持FP32和FP64这种训练才会用到的高精度。这里唯一值得注意的遗漏是BF16,这是 AI 工作负载的常见数据类型,可能BF16是NPU的工作范围。另一个特色是超大规模的ROB重排序缓冲,超过650个微操作,相比之下ARM Cortex-X4只有384个,X1只有224个。

图片来源:AnandTech
LSU(Load-Store Unit)方面,支持加载/存储单元的 L1 数据缓存本身也相当大。完全一致的6路关联缓存大小为 96KB,是英特尔Meteor Lake中P核心缓存的两倍,不过英特尔新一代产品也是96KB。

图片来源:AnandTech
MMU方面,页表缓存即TLB很强,TLB又称转址旁路缓存,为CPU的一种缓存,由内存管理单元用于改进虚拟地址到物理地址的转译速度。目前所有的桌面型及服务器型处理器皆使用TLB。TLB具有固定数目的空间槽,用于存放将虚拟地址映射至物理地址的标签页表条目。PC领域的较高,手机领域的比较低,但目前计算全都转向PC领域,需要更高的TLB,对比ARM Cortex-x3,其TLB只有4路1536个,X4估计是3072个,高通有8路,大于8000个,远比ARM 要强。
硬件表遍历器也是特色。如果缓存行不在 L1 或 L2 缓存中,该单元负责将缓存行移至外围 DRAM,最多支持 16 次并发表遍历。完整的 Snapdragon X 芯片一次最多可以进行 192 次表遍历。

图片来源:AnandTech
L3缓存不大,只有6MB,因为高通的L2缓存足够大,总计有36MB,因此L3缓存可以很小,也有助于降低功耗。SA8295是8MB的L3缓存,SA8775是4MB的L3缓存,减少L3缓存是个趋势。骁龙X 具有 128 位内存总线,支持 LPDDR5X-8448,最大内存带宽为 135GB/秒。在目前的LPDDR5X容量下,骁龙 X 最多可以处理64GB的RAM。

图片来源:AnandTech
GPU方面,与前面几代没什么大的变化,Adreno X1 GPU 架构是高通公司正在研发的 Adreno 架构系列的最新版本,其中 X1 代表第 7代,SA8295与SA8755都是第六代。Adreno 本身基于15年前从ATI收购而来(Adreno 是 Radeon的字母变位词),多年来,高通公司的 Adreno架构一直是安卓领域最强大的GPU。Adreno X1 GPU分为6个着色器处理器 (SP) 块,每个块提供256个FP32 ALU,总共1536个ALU。峰值时钟速度为1.5GHz,这让骁龙 X 上的集成GPU的最大吞吐量达到4.6 TFLOPS(低端SKU的吞吐量较低)。

图片来源:AnandTech
每个uSPTP 提供128个FP32 ALU。还有一组单独的256个FP16 ALU,这意味着Adreno X1在处理FP16和FP32数据时不必共享资源,可以用于小规模的深度学习训练场景。不过车规版应该会取消FP16单元,FP16精度在车上基本用不到,FP32也可以对应FP16。最后,有16个基本功能单元 (EFU),用于处理超越函数,例如 LOG、SQRT和其他罕见(但重要)的数学函数。对于车载领域,GPU算力有1.3TFLOPS就足够,再向上就是要在车内玩3A游戏了,不过该芯片无法支持完整的DirectX 12 Ultimate(功能级别 12_2)功能集,显然这不是高通擅长的,AMD和英伟达更擅长游戏领域。
对于AI运算的NPU,还是高通的六角DSP,缺乏亮点,乏善可陈,高通一句话带过,没有多说。
高通的第四代芯片上车预计要到2026年,以高端目前的垄断态势,换句话说,高通决定了3年后的汽车座舱和舱驾一体将会是什么样的应用状况。整车厂和Tier1只能被高通牵着鼻子走,环顾宇内,亦步亦趋地跟着ARM走是远远追不上高通的,至少在座舱领域,高通已没有对手。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
声明: 本文由入驻搜狐公众平台的作者撰写,除搜狐官方账号外,观点仅代表作者本人,不代表搜狐立场。
回首页看更多汽车资讯
大白兔
0大白兔 小子
0